Starting May 13, new projects are Server-Side Rendered (SSR) and powered by TanStack Start, a modern React framework for building fast, full-stack apps. You don't have to opt in, configure anything, or learn anything new to start using it. Existing projects keep working as before, but get pre-rendering to enable improved readability for crawlers.
This post is for anyone wondering what changed under the hood and why. We'll cover what's different, why we picked TanStack Start, how the new pieces fit together, and what it means for the apps Lovable generates.
In short
Previously we created Single-Page Apps (SPAs) built with React + Vite and deployed as static files. Everything was Client-Side Rendered (CSR), which works well but comes with some limitations. Anything resembling backend logic (sending an email, calling a paid API, hitting a database with a service-role key, etc.) had to live in a separate edge function deployed independently of the app code that called it, living on a different URL.
The foundation of the new stack is TanStack Start, a full-stack React framework with first-class server-side rendering (SSR), static-site generation (SSG), and client-side rendering (CSR) per route, with integrated server functions. This allows for server-only logic to reside directly within your component files, functioning like standard calls while the build process manages the client-server separation. It also benefits our users in many ways.
| Layer | Previous stack | New stack |
|---|---|---|
| Framework | Vite + React Router | TanStack Start (TanStack Router) |
| Runtime | Static hosting (Cloudflare Pages) | Cloudflare Workers |
| Rendering | Client-Side Rendering (CSR) only | Server-Side Rendering (SSR) or Static-Site Generation (SSG) or Client-Side Rendering (CSR) (per-route) |
| Server logic | Edge Functions | TanStack Server Functions |
| Database, auth, storage, realtime | Supabase | Supabase |
| Secrets | In Supabase | Cloudflare Workers bindings |
Why TanStack Start
When we started looking for a new base framework, the constraints were clear. It had to stay in the React ecosystem, be open and independent, easy to deploy anywhere, support server-side rendering so search engines can better index Lovable-built apps, and be maintained by an established team with a strong developer ecosystem. TanStack Start fits on all counts.
TanStack Start's type system is strong and allows for end-to-end type safety, giving clearer guardrails for the AI generating code. The router is the same one many teams have been using for years, while the server runtime sits on top in a way that respects the underlying React server/client boundaries. It is designed to be deployed on any platform that can run a JavaScript server. On top of that, Lovable's own supply chain security scanning and hardened third-party library management ensure that building on Lovable with TanStack is safe and secure.
Rendering: SSR, SSG, and what the browser actually receives
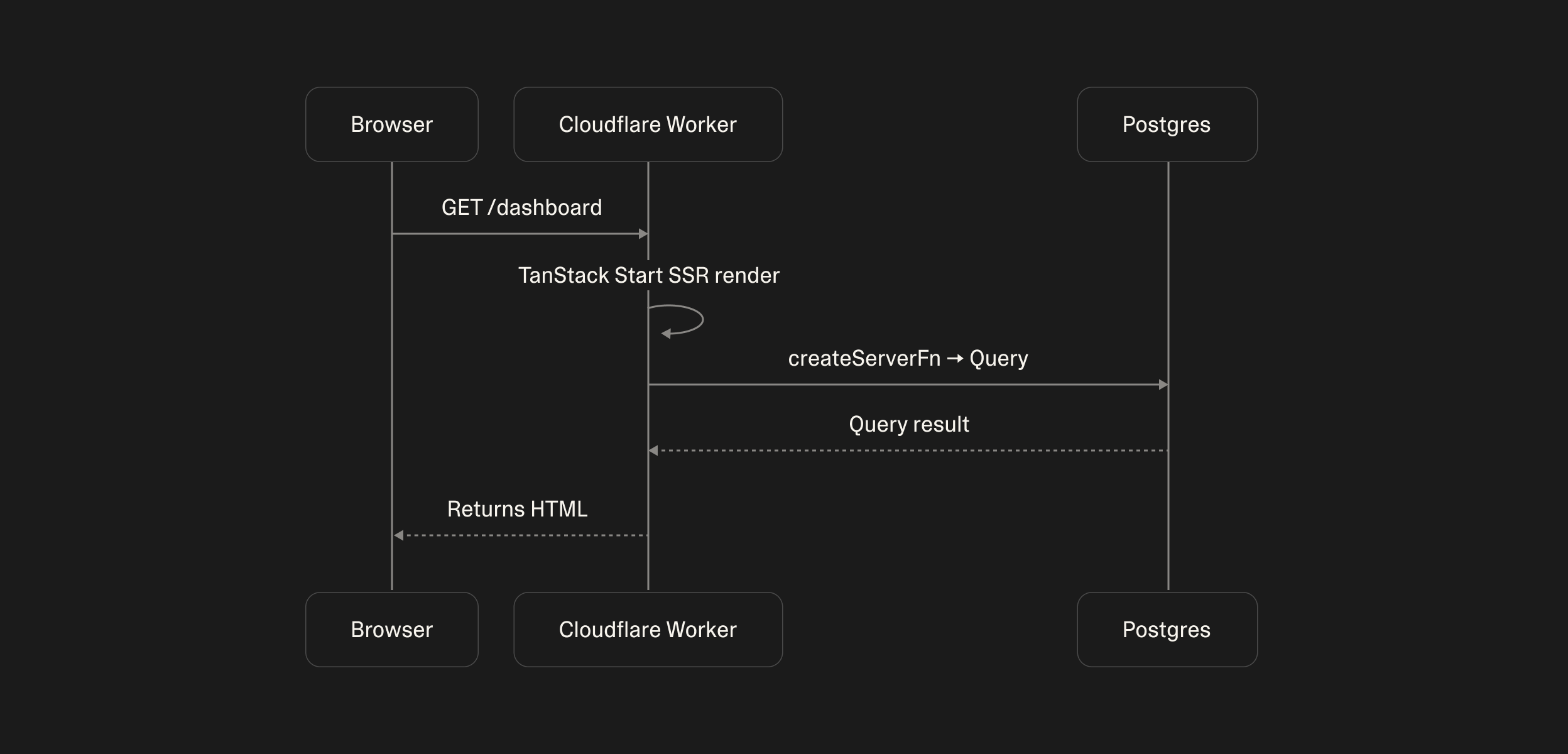
The most impactful change is that pages now arrive at the browser with their content already in them. To understand why this matters, it helps to see what the old behavior looked like.
A client-rendered React app, on first request, sends back a near-empty HTML shell — basically a <div id="root"> and a <script> tag. The browser then downloads the JavaScript, executes it, and only then fetches the data needed to render the page. Two round trips before anything appears on screen. That can be slow and is effectively invisible to a class of traffic that matters a lot: crawlers.
Crawlers vary in what they do with a JavaScript-only page. Google does eventually render it, recent measurements put the median delay at around 10 seconds, with the long tail stretching to hours. Some other crawlers don't execute JavaScript at all, to them, a client-rendered app is just an empty page. In addition, social previewers on LinkedIn, Slack, WhatsApp, and X read meta tags from the HTML directly, so a client side-rendered app shows a generic preview even when the page has perfectly good title and description tags set per page.
TanStack's approach follows SEO best practices because with server-side rendering, the server runs the React tree, executes the loaders, and streams the result as fully-formed HTML on the first request.
For routes that don't depend on per-request data (blog posts, landing pages, marketing pages, about pages, anything where every visitor sees the same thing), TanStack Start can go one step further and prerender these routes at deploy time to serve them as flat HTML, no server execution at all at request time. Lovable's AI applies this automatically when a route qualifies.
The execution model: Where your code runs
One of TanStack Start's core principles is that code is isomorphic by default. Route modules, loaders, and components are included in both the server and client bundles. If something should only run on the server or client, you mark that explicitly with a boundary.
One such boundary is createServerFn. It's transformed at build time by a Vite plugin. In the server bundle, the handler body is included as is but in the client bundle, the entire handler body is replaced with a typed fetch() stub that POSTs to the server's endpoint. The result, you write what looks like a normal function in a normal file, import it from anywhere and the build figures out the environment split automatically.
This model fits how Lovable generates code particularly well. A feature that previously required a separate backend function, deployed independently and called over its own URL, can now live next to the component that uses it. One file, one mental model, and one deploy. The AI marks the server-only parts with createServerFn and the build handles the rest. The advantages are fewer moving parts when something breaks and end-to-end types between the call site and the handler. You don't have to know where each line runs but if you read the generated code, you can tell at a glance and so can the AI when it edits that code later.
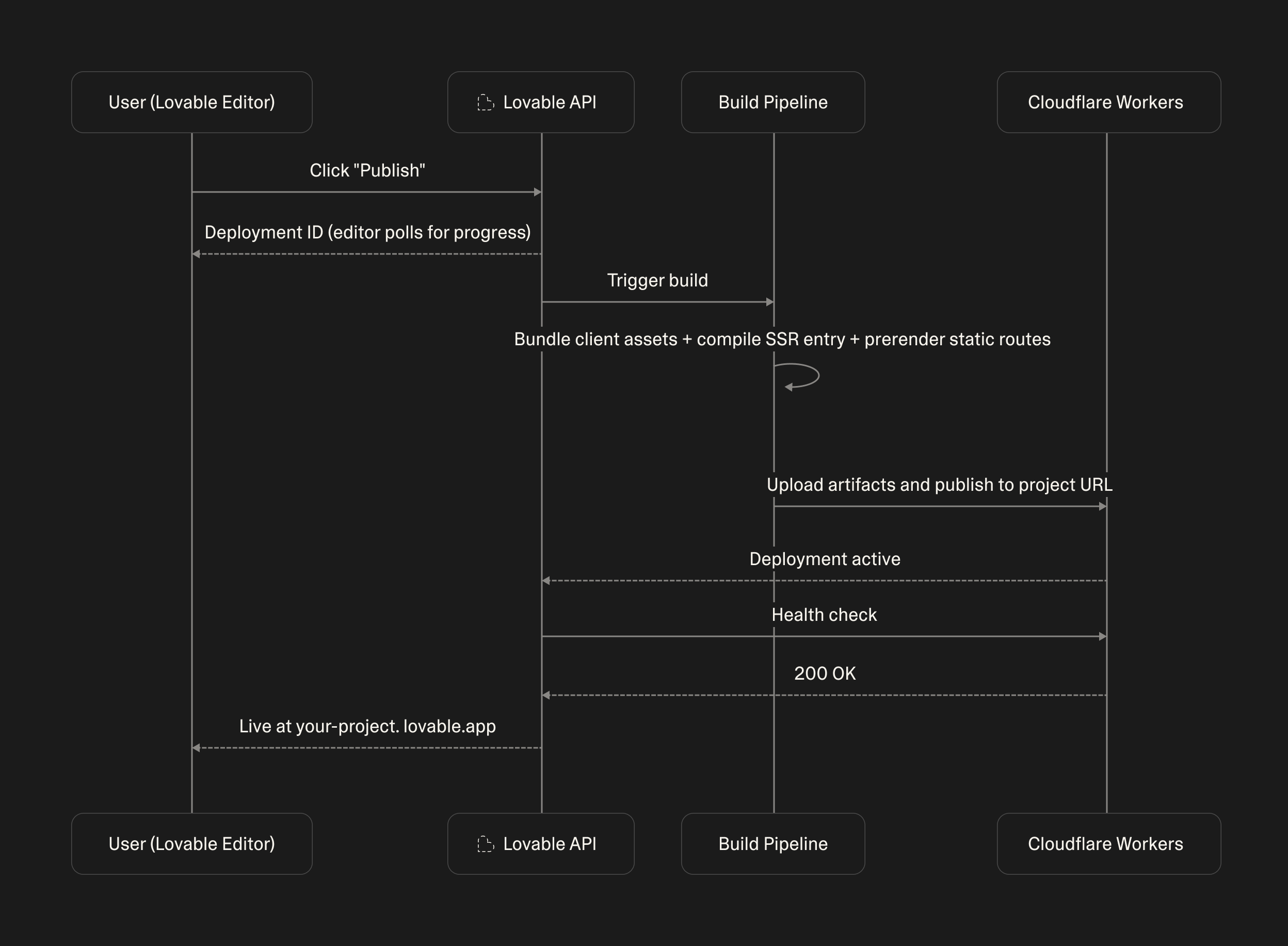
Publishing
Publishing in Lovable still works the same way it always has: you click Publish, the editor shows progress as the deployment runs, and a moment later your app is live at your-project.lovable.app. What changed is what's actually being built behind the scenes. Previously, publishing meant uploading a single-page app's static files to a CDN. Now every publish builds a server-rendered app, pre-generates the routes that can be served statically, and deploys it all as an edge Worker.
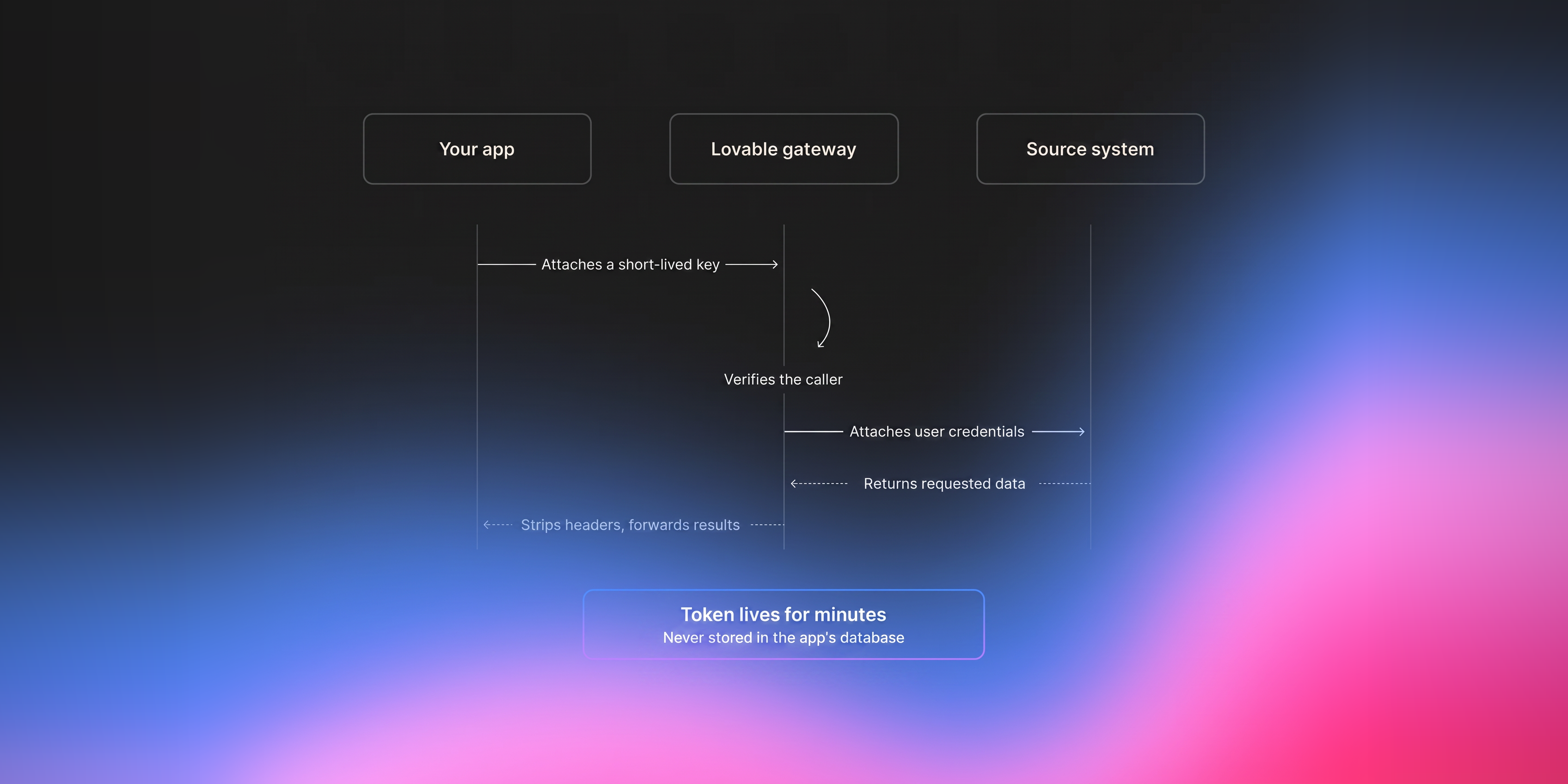
Secrets and environment variables
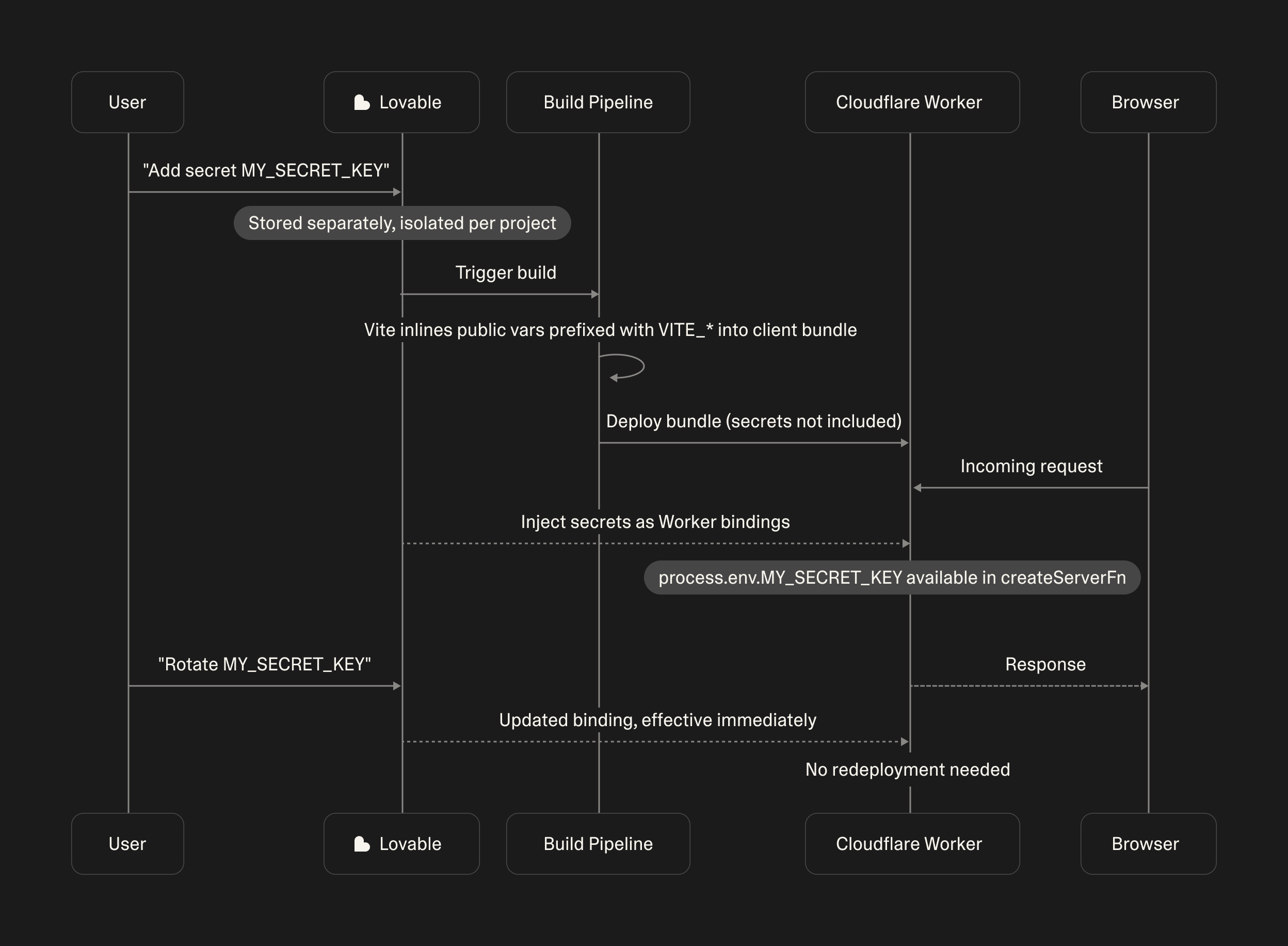
Variables in TanStack Start follow a naming convention. Anything prefixed with VITE_ is treated as public and included in the client bundle at build time, while anything without that prefix is server-only and accessible only from server functions. From a Lovable user's perspective, this is invisible — you add secrets in your project's settings exactly as before, and Lovable makes sure each one ends up on the right side of the line.
What's actually new is how server-only secrets are stored. They aren't part of the deployed code bundle at all. They live separately, isolated per project, and are injected into the Worker as bindings at request time. Because they're decoupled from the bundle, you can rotate a secret and the change takes effect on the very next request: no rebuild, no redeploy, no stale window. The runtime behaviour ensures that secrets never make it to the client bundle.
How the AI knows the new patterns
TanStack Start shipped after most LLM training cut-offs. Without intervention, a model asked to write TanStack code would default to patterns from frameworks it knows better, such as Next.js getServerSideProps or "use server" directives or older TanStack release-candidate APIs. A lot of work had to go into teaching the model the new patterns and conventions.
To address this, Lovable's AI is given a curated set of TanStack-specific rules, injected into the context of every new-stack request. We didn't build this knowledge base from scratch, we've been working with the TanStack team, using the skill they maintain for AI tooling as a starting point and continuously iterating on top of it. The rules are opinionated guidelines written to teach the model the correct TanStack patterns and to steer it away from the ones that look right but aren't. As our usage grows and we observe how the model behaves across real projects, we keep refining the rules so the generated code gets better over time.
TanStack's design also suits how the AI actually reads code. The framework is explicit about what runs on the server versus in the user's browser from the file names (through specific naming conventions like *.server.ts or by utilizing the @tanstack/react-start/server-only modules) and it catches whole categories of mistakes before they ever reach a user.
These rules cover every part of the app that the AI creates, from how things look and work to how data is handled, how users log in, and how everything connects. Because of this, the code the AI makes from the start follows the right new approaches way more accurately.
Better SEO for existing apps
Existing apps today already gain one benefit from the new stack without migrating: better visibility to crawlers through prerendering. When a deployed Lovable app gets visited by a verified crawler, we render the page server-side in a headless browser and serve the rendered HTML. For human visitors, nothing changes, the app still loads as a regular SPA in their browser.
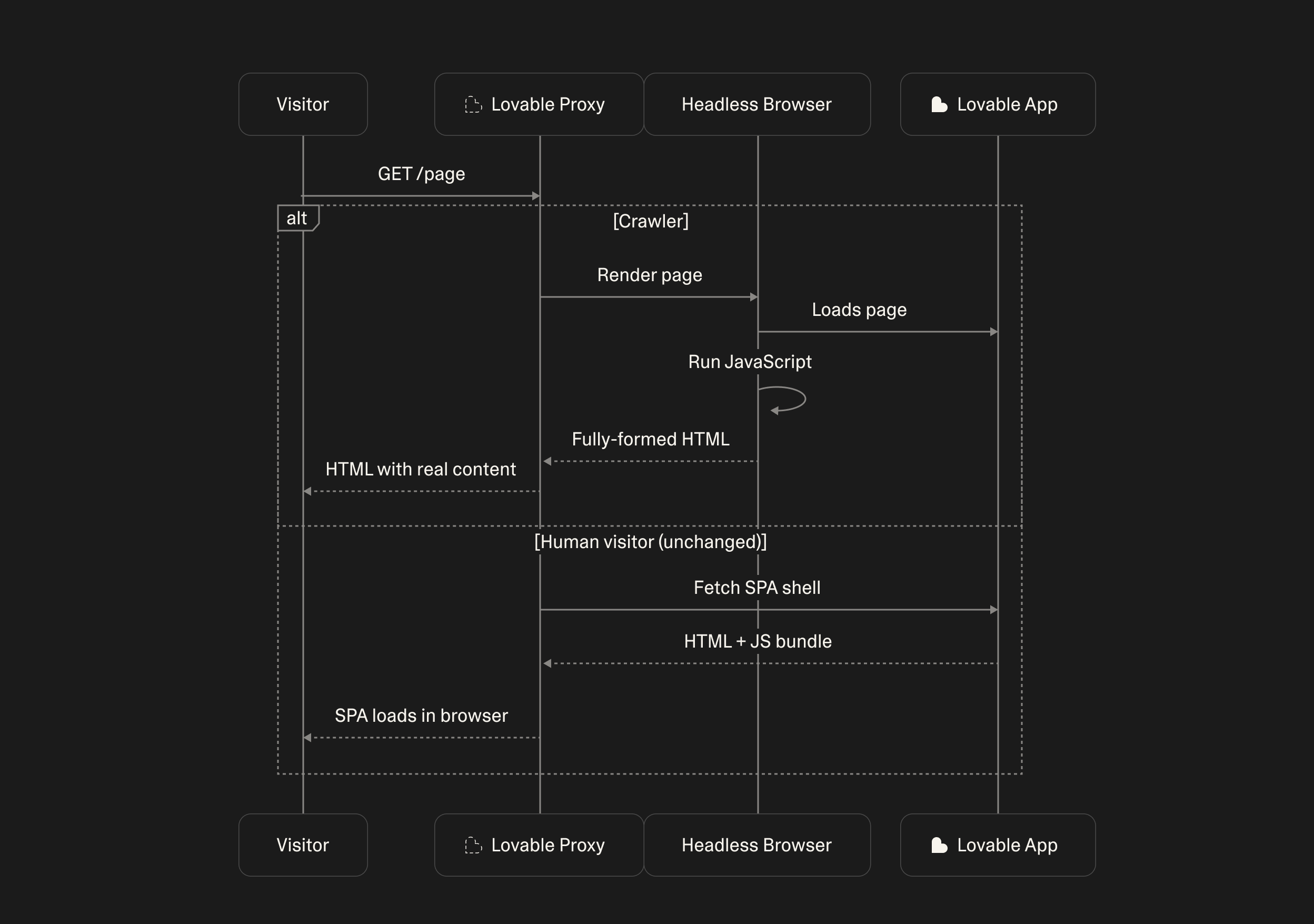
Early results are already positive: across all domains, we're seeing an increase by 2.9% in organic search traffic for apps using pre-rendering and 98.5% in traffic from AI tools like ChatGPT and Perplexity (Also known as AEO or Answer Engine Optimisation).
What this means in practice
Every project you've already built on Lovable continues to run exactly as before. There's nothing to migrate, nothing to update, and no decision to make right now. The new stack only applies to projects created from this point forward. Beyond the SEO upgrade mentioned above, we are actively working on a path to bring the rest of the new stack's capabilities to existing projects too.
If you build something interesting on the new stack, we'd love to see it. And if rebuilding the foundations under generated apps sounds like the kind of problem you want to work on, take a look at our open roles.