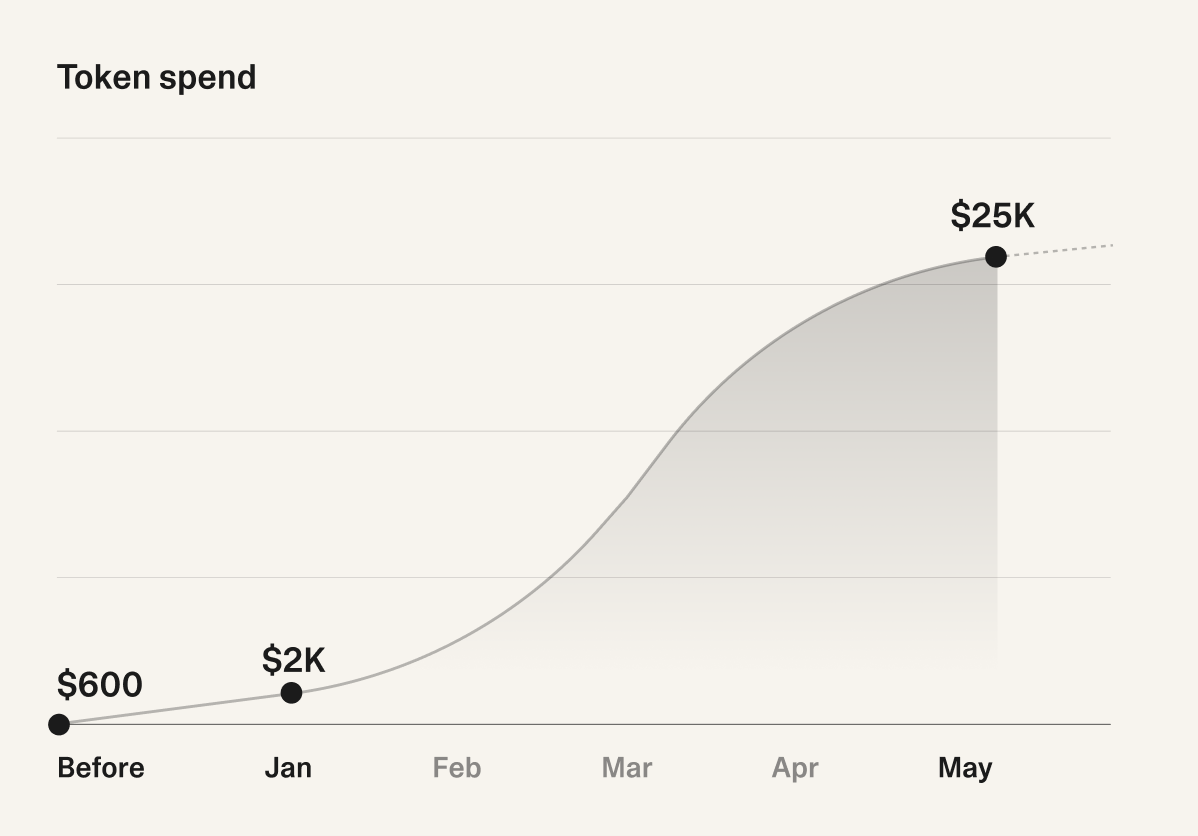
I joined Lovable in January this year. Before that, I used maybe $600 of tokens per month on my coding tasks. Once I started here, a larger scope, a larger project, and the freedom to use as many tokens as a problem warrants brought my individual spend to ~$25K/mo in May and an overall spend of ~$85K since January. Here's what happened when I pushed harder than most, and what I learned along the way.
Development process
In January 2026, my agentic coding process involved plan mode, permission requests, and classic code review. A productive week meant 20-30 merged PRs.
As of June I have a dedicated agent that writes tasks for the other agents, with multiple levels of implementation and review agents. For large changes, the working unit is a 10-PR stack instead of a single PR. Human review happens for the important decisions and rarely for the code. A productive week now means 150+ merged PRs.
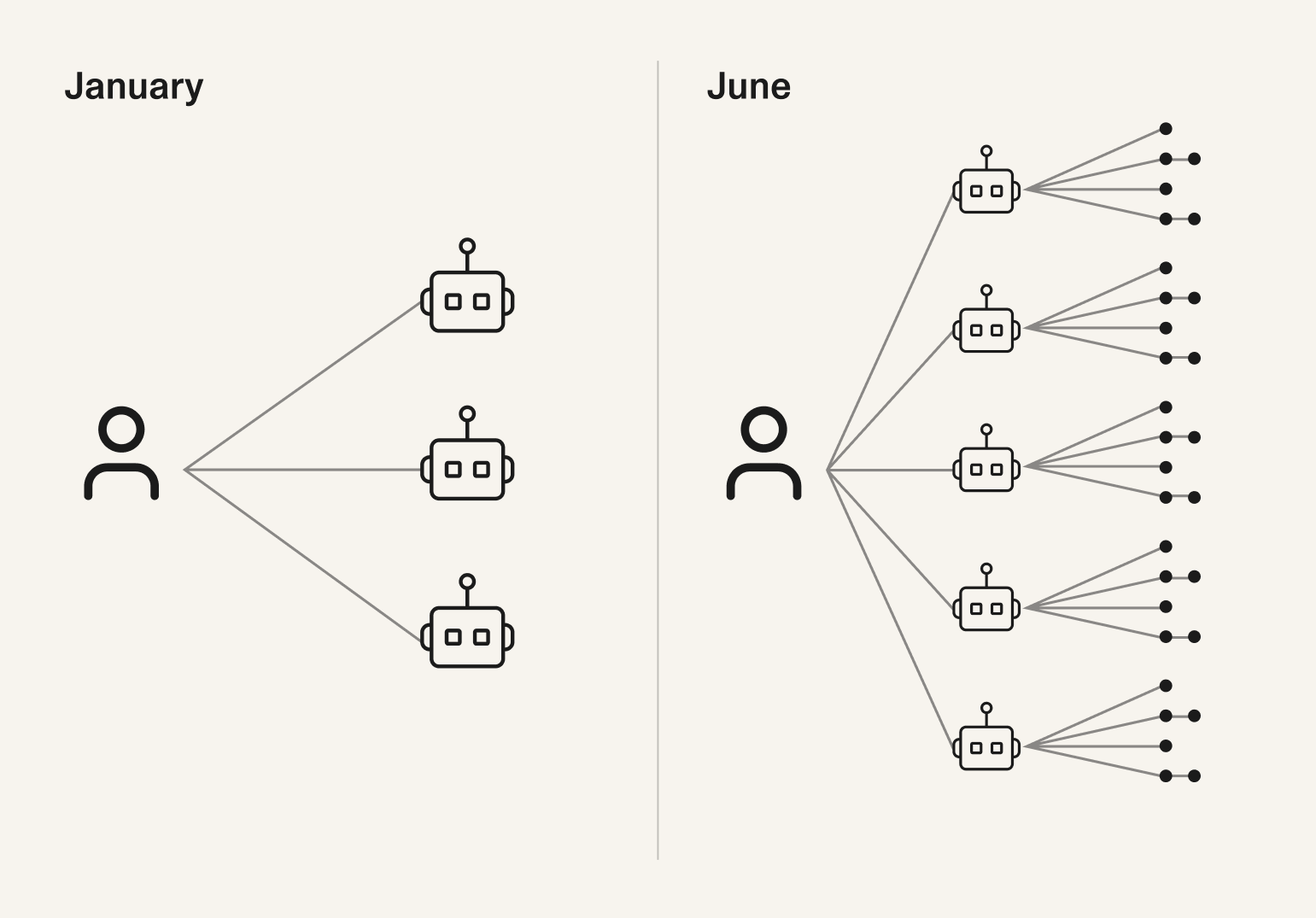
January: solo dev plus a few agents. June: one human over 6–7 agents, each with its own swarm of subagents.
Spend structure
About 75% of my tokens are spent directly on implementation. The other 25% (and growing) is spent on all forms of automation: AI reviews outside of my dev environment, post-merge AI reviews, and all kinds of regular automated tasks. I predict that this share will only increase as more and more work shifts out of the code-creation PR loop.
Human review is an exception
The transition from human-written to AI-written code in many ways is a new level of abstraction, like the transition from assembly to higher-level languages. Back then, people pretty quickly stopped looking directly at the output from the compiler. The same is happening with code review today. Reviewing AI-written code line-by-line isn't practical or a good use of anyone's time. And the usual answer to problems created by the use of AI is to use more AI, so you switch to AI reviews by default. Those are getting notably better over time.
What I've seen work at Lovable is reserving human review for the most impactful changes. However, this often doesn't happen in the form of traditional code review on a PR. Instead, it's happening at a higher level with RFCs and ADRs. We often pair debug hard problems or do whiteboard sessions in-person to get aligned on a new initiative. The important thing here is to apply human attention where it gives the most impact. For example, a single discussion of system design or an infrastructure choice may change our system more than 50 implementation PRs would. That's why we try to shift human attention where it matters the most — and it's not code review.
The problem is that when code review goes away, we lose a lot of the secondary benefits that are unrelated to approving changes line by line. Code review used to be a learning tool, and a way that knowledge diffused through an organization. It was an automatic discovery and alignment mechanism for style and architecture choices as well. As a discipline, engineering needs to find a way to preserve these second-order effects in a world where code review is largely automated. I don't see any good solutions yet, only space for new experiments.
Change risk classification
Bypassing human review on most PRs raises another question: can you scale this to a large organization where new joiners are expected to ship something to production in their first days? Turns out: no, at least if you do it in a naive way. The system needs to be reasonably resilient to well-intentioned enthusiastic developers who might not know what they don't know. I ended up building an AI workflow for PR classification by risk level and hard-enforcing human review on high-risk PRs to keep the overall risk levels reasonable.
So, you need to identify which changes have an unusually high and unusually low risk of breaking production. How do you classify your changes? Common sense plus LLM-based classifiers get you quite far. Is it infra or auth related? Always high risk. Is it publishing a blog post? Low risk. Is it too big? Does the author's team own the majority of code containing the change? Is it a production feature or something experimental? And so on.
The core of our classifier is a single markdown policy file. The agent then reads it together with the PR diff and metadata and decides where a particular PR falls on size, risk level, and code ownership. Then there's a large but boring deterministic tool that applies the policy based on classification decisions, and some GitHub action and ruleset piping to allow or deny merging pull requests in their current state. Of course it's all AI-generated — once you know what policy you want to apply, designing a system around it is pretty much a solved problem.
If you automate such risk assessment you can require human review for high-risk changes, slow expensive AI review for medium-risk changes, and quick and fast AI review for low-risk changes. And a larger and larger share of review conversations increasingly happen around changes where discussion would bring the most benefit.
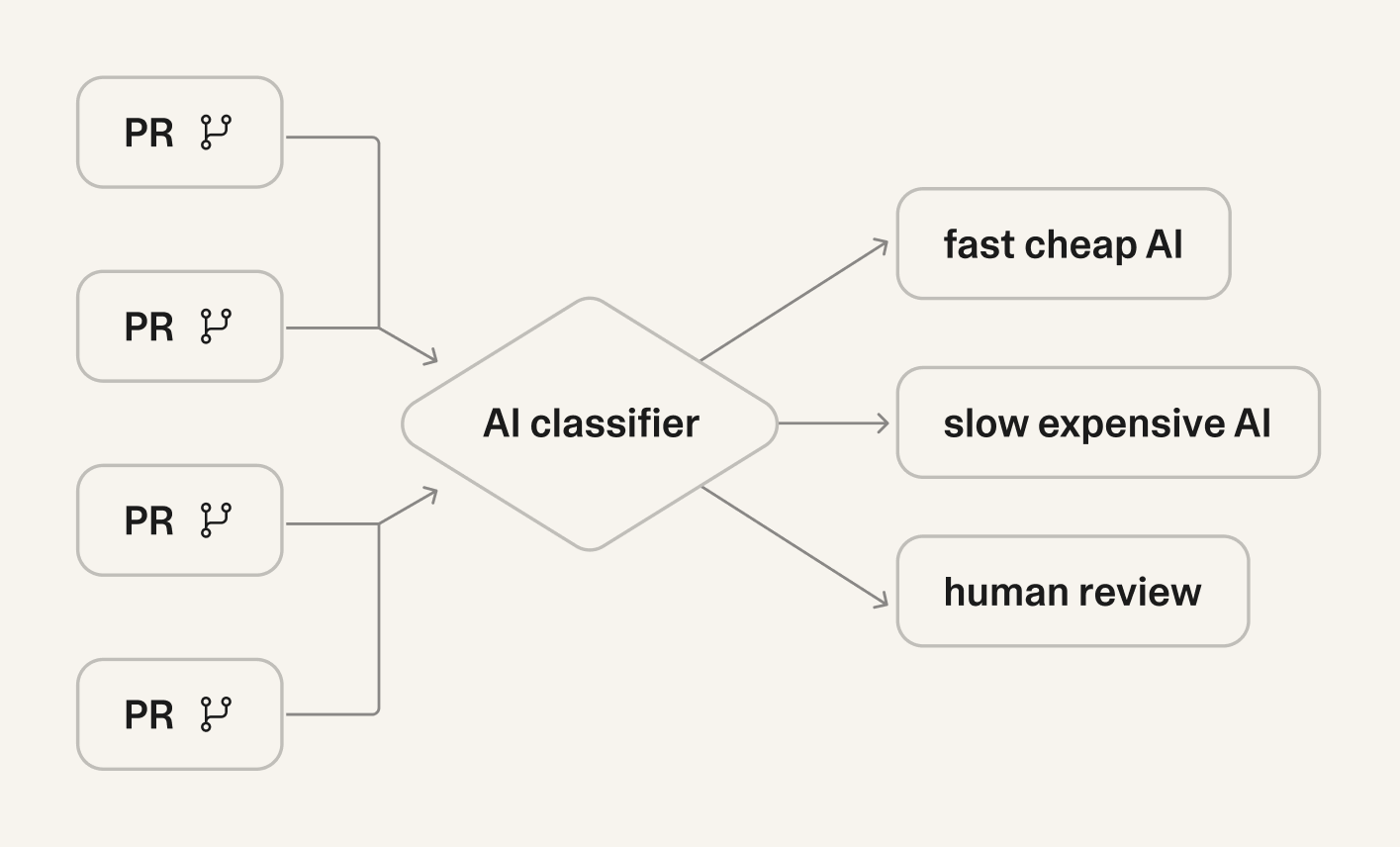
PRs entering a classifier and splitting into three lanes: fast AI, slow AI, and human review when escalation is needed.
All the shapes of AI code review
During my time at Lovable we tested at least 3 AI review tools that work on PRs and a few more that work locally in the development environment.
Tradeoffs on CI review are ... interesting. You either get something quick and cheap, but there's a significant chance the agent sounds stupid and/or it misses something important. Or it's expensive and takes forever (30m per pass is not unusual) but is typically accurate. I find that the slow and expensive variants of AI review were already more useful than the median human review a few months ago. And the agents keep getting better.
There's also local review. It can be as simple as a "review this code" prompt or it can evolve into a sophisticated skill with subagents, a findings tracker, and all sorts of bells and whistles.
The biggest win here is doing local review at all compared to relying on CI checks. The next big improvement is delegating review for specific aspects (like correctness, performance, code reuse) to multiple subagents, then letting the main agent aggregate and deduplicate their findings. We put a lot of effort into sharing what good code should look like with the agents (through skills, AGENTS.md, style guides next to code, etc.), and then people independently experiment with how they run local reviews using this knowledge.
I quickly noticed that I rarely dispute local review findings. Hence the natural next step: my review skill also triages and fixes the findings, all autonomously. Separation between discovery and evaluating the findings improves overall performance, since each agent focuses on its own thing. Fixing affected findings, curiously, does not need its own context — the agent that can evaluate the finding well can fix it well too.
If some suggested change is wrong, I'd rather find and fix the root cause than fight the agent to fix a particular run. The agent is usually wrong when it doesn't have enough context, and you fix it by improving your knowledge files, style guides, etc.
I think you want both kinds of AI reviews in place. CI review is the common denominator and the safety net. The local review-and-fix setup is the real workhorse that hopefully does the bulk of the productive work — but the unsolved problem here is how to best share this setup between people.
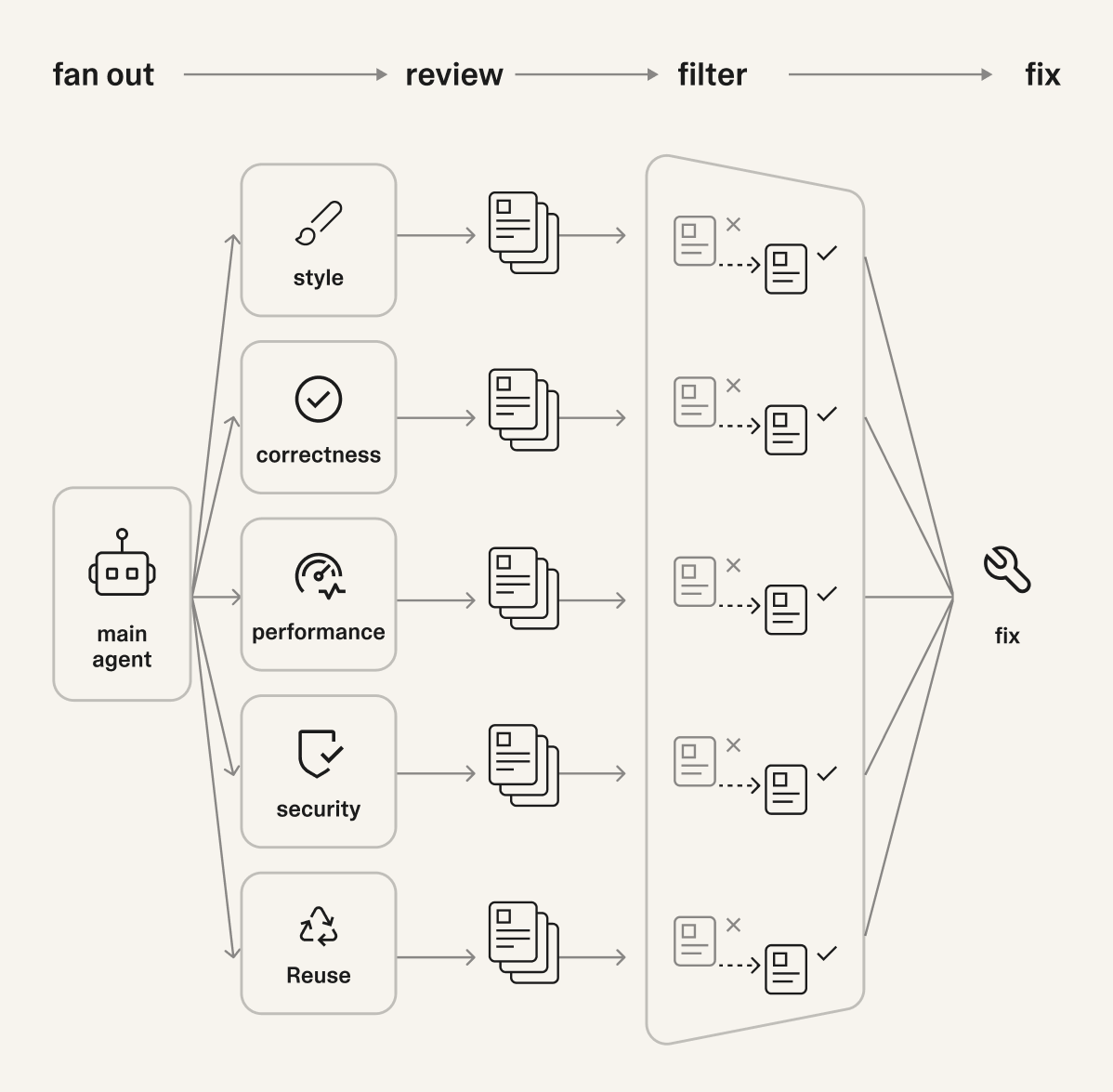
Main agent dispatching correctness, performance, reuse, and security subagents, then aggregating findings and fixing them.
Will PRs survive the agent age?
I've seen a claim that PRs will turn obsolete in the age of AI coding. And that stacked PRs are only relevant when you rely on human review. As of today I don't believe either claim.
A PR is a good abstraction for unverified changes. CI/CD works on PRs. Almost all pre-merge testing setups work on PRs. How else are you going to verify changes — "Works on my machine"? So, perhaps PRs will stay a useful abstraction even if the process around them changes a lot. Compare this to how file systems and their base abstraction can be traced to what UNIX developed for very different underlying hardware than what we have today.
As for stacked PRs, I find them incredibly useful for context management and risk management. The quality of AI code review drops sharply when your change gets big enough. One time on my team, a fellow developer got AI review approval on a big, 6K-line PR. I asked to split that PR into a stack. And when it happened, the same AI reviewer started finding new real issues in the resulting smaller PRs. After that story, engineers at Lovable increasingly distrust large PRs; they were never reviewable by humans and now we know they aren't reviewable by AI either. Maybe model advances will change this one day, but we're not there yet.
Managing my own attention
When you have a magic cognition machine that spews out an unlimited amount of code, mental context switching becomes one of the hard limits on overall productivity. Some thoughts on scaling here.
Fast mode is a great deal, makes total sense for interactive back-and-forth sessions. For example, I try to always plan in fast mode. You're way more productive than if you try to work with 5 interactive sessions in parallel. That said, I see no reason to run fast mode for non-interactive tasks. There's zero value in an overnight task being done at 3 AM instead of 5 AM, for example. And during the daytime you typically want to focus on one most important thing at a time — other tasks can proceed more slowly in the background.
Task autonomy is the key. The agent should have the context and tools to drive the task as long as practical. Some variant of auto mode or YOLO mode is required; you want zero permission requests. Sometimes this means you'll want to add dedicated tools to allow the agent to safely perform some actions that are normally risky. For example, my agents aren't allowed to merge PRs with the gh CLI, but they are allowed to use Graphite's "merge when ready" with additional safeguards related to branch freshness, lack of open PR discussions, etc. gt CLI invocations are then wrapped into a custom Node.js script covered by unit tests to ensure an agent has no room for mistakes. All of it is written down as an agent skill — it was quite a bit of work to set it all up, but this effort pays off in never having to fix a bad merge again.
I want to validate that the agent built the right thing. I want to delegate as much verification work to the agents as safely possible. Sometimes it's all of it, sometimes you need a human in the loop. Ideally, I want to batch all the validation work and do it exactly once per PR stack. This usually means validating the end result at the top of the PR stack and making sure you don't need to validate every intermediate PR in that stack. This means you need to be sure that your process produces atomic PRs by default that would be safe to merge individually. And you need to be sure that any exceptions are brought to your attention by the agents.
Managing the agents' attention
Agents need support to be able to build large changes autonomously. Here are the key parts of my setup for this.
Beads as external task tracker. Large tasks may need more than 1M tokens of context. Quality degrades and cost grows with the context window. I don't trust that auto-compaction is close enough to manual context management. Also, agents sometimes crash, and I want some durable handoff vessel to simulate foreman-worker interaction — subagents don't work for this. Bottom line, this all requires some form of reasonably durable task tracking. I use Beads with a local setup without syncing to git. Maybe some other tools would work just as well.
Subagents. I delegate large context consumers and distinct subtasks with their own goals to subagents. Code exploration. Code review focused on specific properties. Agents are getting better at seeing and using delegation opportunities, but for now it's still better to structure your typical workflow in a way that uses subagents deterministically. And you get some cost savings when simpler tasks can be delegated to smaller models.
Small PRs. I wrote about it above, but keeping PRs to tens to hundreds of lines of code makes sure agents don't run out of context during implementation and review. After I taught my agent about stacked PRs and recommended PR size (via a shared skill) it reliably does a good job of separating bigger tasks into multiple PRs.
New context per task. Basic hygiene, IMHO: never reuse context for multiple tasks. /clear is free, reversible, and takes just a few seconds to type.
Sidenote: task tracking
One thing that I strongly believe here is that task tracking for humans and task tracking for agents should be separate. I've seen Linear tickets with walls of text from agents' chains of thought in them and it's not a pretty sight. Most of the text agents generate is ephemeral and should be treated as such, staying user-specific and never exposed to other humans. If writing to Linear is deliberate, we'll have less slop there.
A factory that builds itself
How do you improve your development process? You locate the bottleneck, think hard about ways to improve throughput there, apply those ideas, then repeat the loop.
Some observations on this:
Agents are good at writing skills. I think the last time I wrote a skill manually was in January. I tried asking the agent to do it and I never looked back since. Try turning every repeated workflow into a skill and try iterating on skills often. One good trick is to ask the agent about skill improvement ideas at the end of the task. Lovable uses a very similar idea for self-improvement already: We gave our agent a vent tool.
Longer-form reflection also works. I regularly ask something like "Look at the last 100 PRs I merged, including PR comments and their resolutions, and suggest improvements" and get a lot of good suggestions back, which I then ask the agent to implement.
CI/CD and DevEx tools should be ready. A lot of improvements were made by our DevEx team at Lovable to make sure our systems scale to a 10x volume of changes and will continue scaling beyond that.
Inspecting your past work is a goldmine. Every time I feed my agentic session logs to an LLM to find insights I get something useful back. Agents overcome some small friction points all the time. Every now and then something derails an agent completely. All of it is a potential fuel for a self-reflection loop that improves your setup over time.
Sharing the context is easy. Just put everything into git. Everyone in the development team (and their agents) then automatically gets synchronized up-to-date knowledge about how things work, how code should be written, etc. Written knowledge used to benefit primarily remote team members in the pre-AI age and now the agents become the primary consumers. This means that office-first Lovable has more reasons to write things down than a fully-remote company had a few years ago.
Sharing is culturally encouraged.
Sharing skills is hard. It's still a largely unsolved problem: how do we share the best ways to do agentic development? There's a Slack channel where people showcase elements of their development workflows; there's a demo session every now and then; knowledge exchange naturally happens when people work next to each other. And yet I feel that we're inventing new workflows and techniques faster than we tell our colleagues about previous ones.
Is it worth it?
During the first week of June I merged 293 PRs, and have found no production defects tracing back to those changes so far. The latter part is a bit of good luck — I think 2-3 minor and 1 major defect would be acceptable for this volume.
Was it worth it? My current productivity is simply beyond the reach of old unassisted development techniques. I feel there's no going back in that sense.
Is it better than hiring proportionally more developers? That's a hard thing to balance and every organization will arrive at its own equilibrium.
Is there a better way to spend money on tokens? Well, tokenmaxxing is a foolish and short-sighted behavior. You have to have a clear purpose. What ultimately matters is outcomes, not how much work you did to get there. And the optimal amount of attention devoted to spend efficiency is not zero. Maybe it's 5% for us right now? 95% should still go to finding new, better ways to solve more problems by applying more tokens to them. Model capabilities evolve so fast that the surface of exploration is growing faster than we can explore it. The opportunity cost of exploring less feels too high to justify even 10% of attention to token efficiency.
Overall it's an amazingly fun ride so far. Can't wait to see what's beyond the horizon. I expect the next $85K of tokens will go towards finding new ways of making our product better. When you can create previously unthought of amounts of software quickly, what do you do with this power?
If this sounds interesting, we're hiring.