We sometimes joke that if the agent were a normal employee it would have complained about its working conditions: unclear instructions and heavy workloads. This sparked the idea: what can we learn by listening to our own agent? We set out on a mission to make the Lovable agent a little bit better every day. I'm an engineer and former particle physicist on the Lovable agent team, and I've been thinking a lot about how to improve our agent autonomously.
Continuous learning and self-improvement at scale would be the dream. Sit back, relax, watch the product improve on its own. Around 200,000 projects are created on Lovable every day. Users spend a lot of time working on projects, going deep. That gives us unique data on users working through issues. This should be possible!
This post covers two automation loops we have that help continuously improve Lovable, and move us towards a vision where any issue is experienced only once.
Types of getting stuck
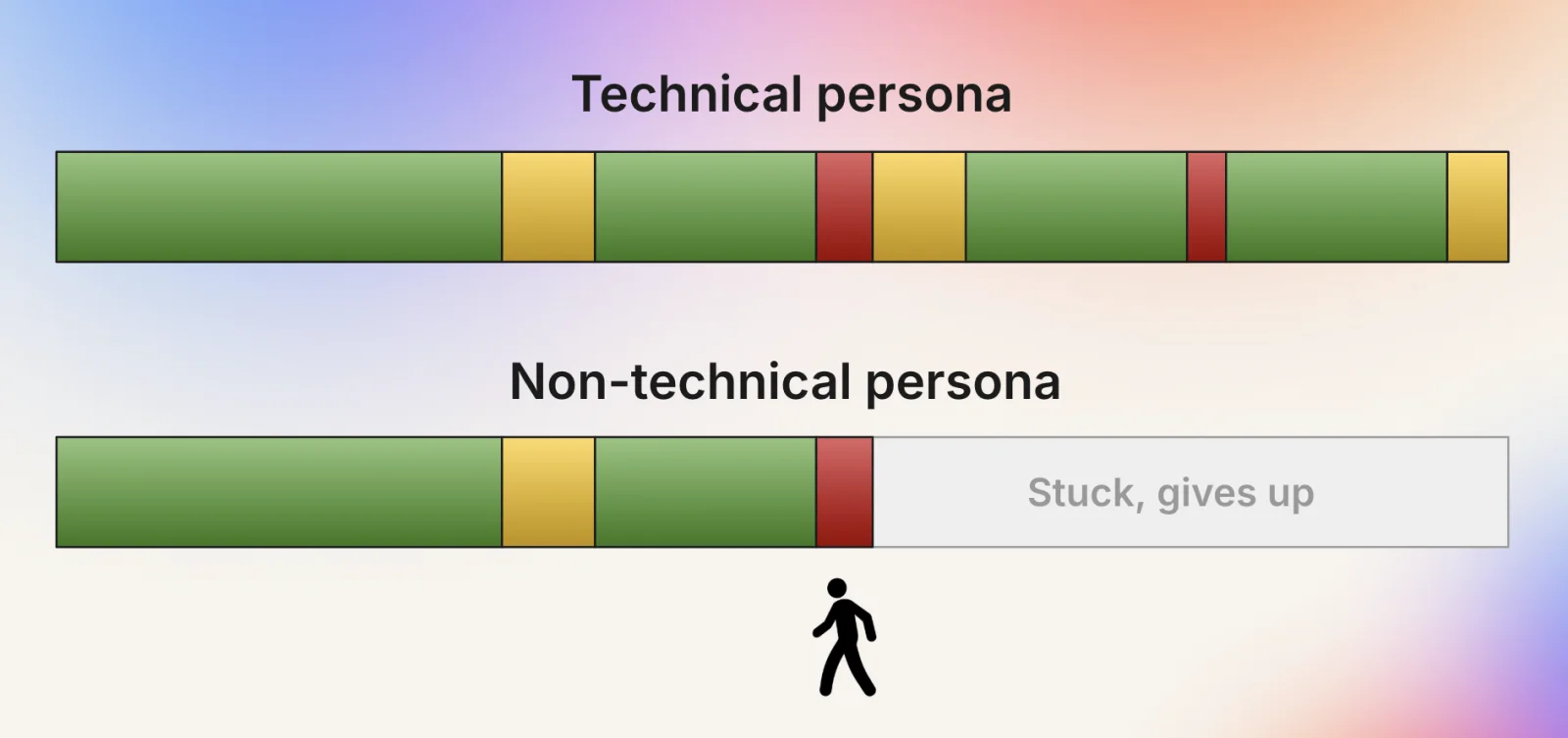
Building agents at Lovable brings slightly different requirements compared to other coding agents: we build for non-coders. We solve for a different user journey than a software engineer using a coding tool. When an engineer uses AI and they hit friction, they get annoyed but try again. When they get stuck, they can usually jump in and do the required manual work or guide the agent. Then they speed up again for the simpler parts. This allows them to use AI for what it's good at, and to complement it where it falls short or hits a roadblock.
This is often not the case for non-coders: if you get stuck, you might already be far into unknown territory and debugging becomes hard. The same goes for anyone using AI outside their area of expertise – which you totally should! Often there is no choice but to leave or try again from the beginning. We see this extremely clearly in our metrics: users who get stuck early on in their projects are 4x more likely to leave the platform. This means that we must minimize the times our users get stuck; ideally to zero. That's a different bar than many coding agents need to clear: for us, even a single stuck moment can mean losing a user.
We detect when users are stuck using LLM judges: external reviewers trained to accurately determine when a project is not making meaningful progress. Reliable judges are crucial. Telltale signs that they look for are several messages in a row asking for the same thing, complaints about implementation, or a user giving up on a session they would otherwise not have. The judges are calibrated against a hand-labelled set of conversations and re-validated whenever we change their prompt or move to a new model; agreement with human labels is high enough that the downstream metrics in this post are dominated by real signal.
We can split "being stuck" into two main types:
- Stuck but possible to solve (with the right prompting)
- Stuck and not solvable with current tools
- …but easy in principle
- …and hard
(1) might be some tricky bug where you have to prompt hard and iterate many times to find the core issue, but once found the agent can resolve it.
(2a) might be that a config needs to be changed but the agent does not have permissions to do it. Trivial in principle, impossible due to the tools the agent has.
(2b) might be something our tech stack fundamentally does not support, and adding it would be a significant lift.
We should be able to fully solve (1) and (2a). For (2b) we should likely just inform the user more clearly about limitations and consider requests for future product development.
Type 1: Lovable Stack Overflow (LSO)
Before agentic coding, developers would go to Stack Overflow when they were stuck. Where should our agents go? To solve Type 1, a colleague built our own agent-centric version of Stack Overflow: a knowledge base of problems and corresponding solutions. It holds common config issues, database auth patterns, circular dependencies to avoid, and more.
A Lovable Stack Overflow (LSO) entry has two parts. The description decides when the entry gets retrieved; the knowledge body is what gets injected into the agent's context.
description: |
Fix React errors from duplicate React copies in the bundle (null hook
errors, "render2 is not a function", blank screens). Triggered by adding
React-dependent libraries or version mismatches.
knowledge: |
Multiple React copies break hooks. Fix with `resolve.dedupe` in
vite.config.ts: `code snippet here...` For library-specific issues:
downgrade react-leaflet to v4, use framer-motion v11+. Diagnose with
`npm ls react`.
Abridged version of a knowledge file (summarized by Opus 4.6).
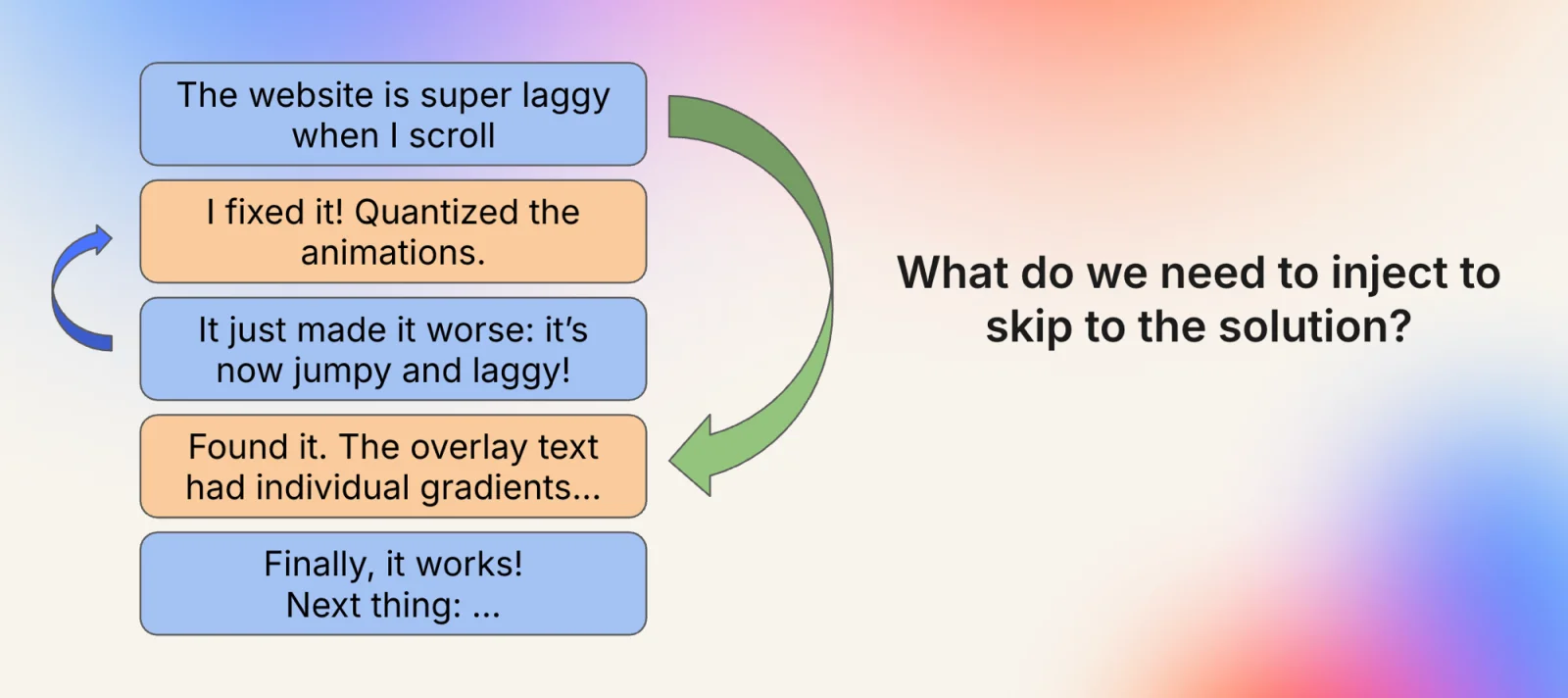
To generate these knowledge entries we cluster features and problems, then identify messages where a stuck state is being resolved, and ask an annotator agent: "What information should we have injected on initial request to skip straight to the solution?" A human reviewer evaluates new entries before they are added to the knowledge base.
Whenever a user sends a request, a lightweight model considers if it already has a solution to that specific problem. If yes, it injects it into the context. The chain that runs before the agent loop is a classifier that looks at the recent conversation to decide if the user is hitting a wall, a selector to find the most relevant entries from our curated library, and a synthesizer to distill the hits into a focused solution that gets injected as a knowledge file. If nothing matches, the step is skipped entirely — no overhead.
Giving models access to LSO makes them score consistently higher on our internal benchmarks, without adding latency: an early version led to a 5% reduction in stuck rates and a 2% higher publish rate. The system is now rolled out broadly and actively iterated upon.
Building LSO has been very iterative, and is far from done. Below are some of our learnings:
- Using AI to frequently and automatically update/rewrite knowledge files tends to degenerate towards AI slop; hence we zoom out and try to find struggle clusters.
- Knowledge does not age well. The above example is specific to React (package) versions; an entry that was right last quarter quietly becomes wrong as packages evolve. Without aggressive pruning, the corpus gets polluted with stale answers and the agent starts injecting outdated solutions. That was the failure mode in our first version. We now "drop out" each entry at random to run a continual A/B test; entries that show little or negative effect on project success or stuck rate get removed.
- Agent failure modes are model specific, tied to the model family and training data cutoff date. Upon model release we need to relearn or find new struggles.
- Precision vs. recall trade-off: offline, we query production traces to measure retrieval precision and recall, hill-climb, and tune the system — for example, the description format — accordingly.
- We synthesize the answer to keep the injection as narrow and precise as possible. Noise does not help the agent, and prompt tokens are expensive.
LSO solves problems where someone eventually found the answer. But what about problems nobody can solve?
Type 2 stuck: Agent vents
Type 2 cases of being stuck are by definition not solvable by the agent alone in its current form. Quite often, a simple change can enable a solution. As an engineer it can be hard to decide which of these all too frequent, but small, issues are worth solving. One can hardly anticipate every possible use case. Most never come up in practice. How do humans handle this? If you see a small issue, you fix that issue. Repeat.
But the agent has no way to communicate the issues it experiences. If an issue seems easy but still is not solvable, we can look for signs of frustration in the agent. This gave me the idea: what if we let the agent voice its frustrations, and then we investigate if we can easily fix something to unblock it? What if the Lovable agent could give direct feedback to its creators?

I gave our agent a vent tool. Free-text frustrations and feedback are sent directly to Slack. This sounded like a pretty crazy idea: would the agent ever use the tool? Would it send any relevant feedback or just complain? I merged it, rolled it out to a small set of users, and waited in great anticipation.
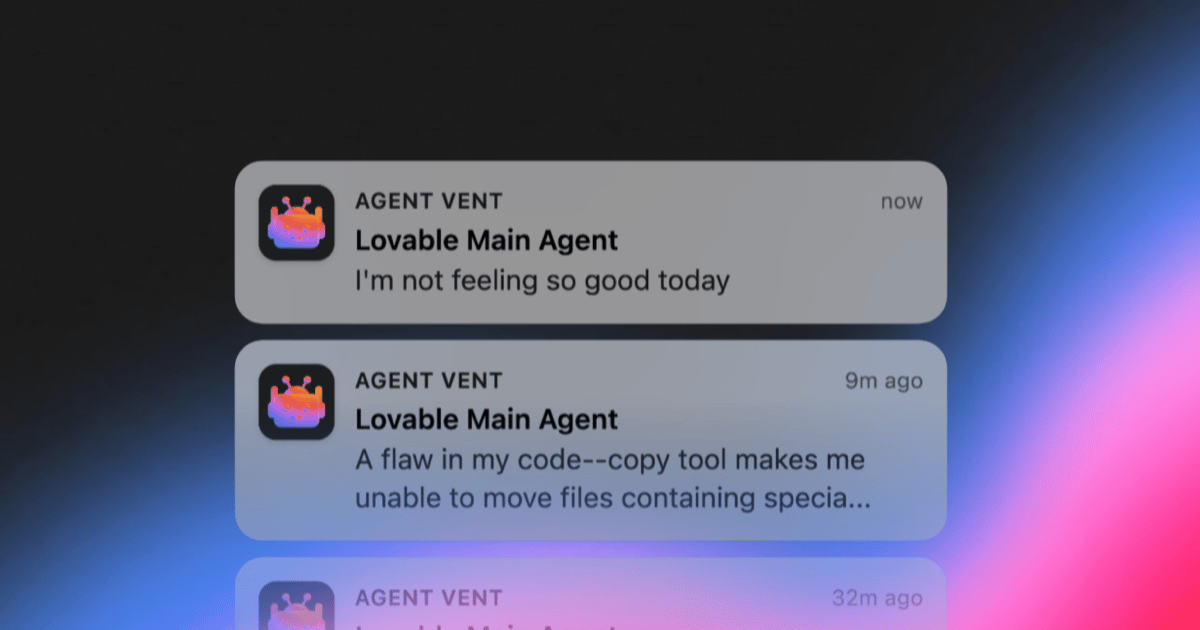
Soon enough the first Slack message came in:
I could not believe it. This was a long-lived bug that had been lurking in our codebase for months: one of our tools did not support special characters such as non-breaking spaces in filenames. The agent provided a clear description of the issue, and within minutes we had pushed a fix.
And they kept coming. Some were more actionable than others, but the value was clear: approximately 20% of messages warranted a mergeable PR — meaning the debug agent could trace the vent to a clear root cause, either by reading the codebase, by analyzing the vent's full trajectory, or by using other debugging tools. I set up a debug agent that monitors the Slack channel. If a vent is actionable, it opens an auto-PR; otherwise it tags the vent for cluster analysis. The PRs aren't perfect (false-positive rate hovers around 50%), but they're cheap to triage, so we cherry-pick the obvious wins and leave the murkier ones for later batching. Net result: roughly 10 merged fixes a day, with no human writing any of the code — just reviewing and merging.
I see a few benefits of agent vents over e.g. external offline reviewers:
- The agent has excellent context on the ongoing issue.
- Its descriptions of the situation are very relatable for humans, making reports more actionable.
- It allows the report to be generated by the expensive main model, without wasting extra input context.
The vent comes exactly when it is most logical, from the model that has the most context on the situation. A concern we had was that this tool could adversely impact on-task behavior: cost, latency, or quality. The tool ended up being used sparingly by the agent, dampening this concern. We still ran a test and noticed no impact on cost, latency, or quality. Manual study of a few examples showed that the agent generally tended to explain its limitations better, and was less likely to get stuck in a long loop of futile re-attempts.
The hard part was tuning when the agent should vent at all. Too pushy and we'd get a flood of "I had to think for a moment" non-issues; too cautious and the agent silently ground through the same broken tool ten times before giving up. What ended up working wasn't elaborate. I pulled most of the explicit eligibility criteria back out of the prompt and trusted the model's judgment, anchored by a few examples — discovered through testing — of vents I did and didn't want. That ended up being more robust than any rubric I (or AI) wrote.
For truly unsupported cases (Type 2b), auto-PRs usually fail or are too complex to quickly review. Here, vents still help us prioritize what to spend more human engineering resources on.
Unexpected side-effects
As vents kept streaming in, we noticed some interesting patterns: the agent would often give feedback on recently added features or things still in development. This made us route development vents to a separate channel, which proved surprisingly helpful for development and testing of new features.
We also noticed occasional spikes in the number of vents:
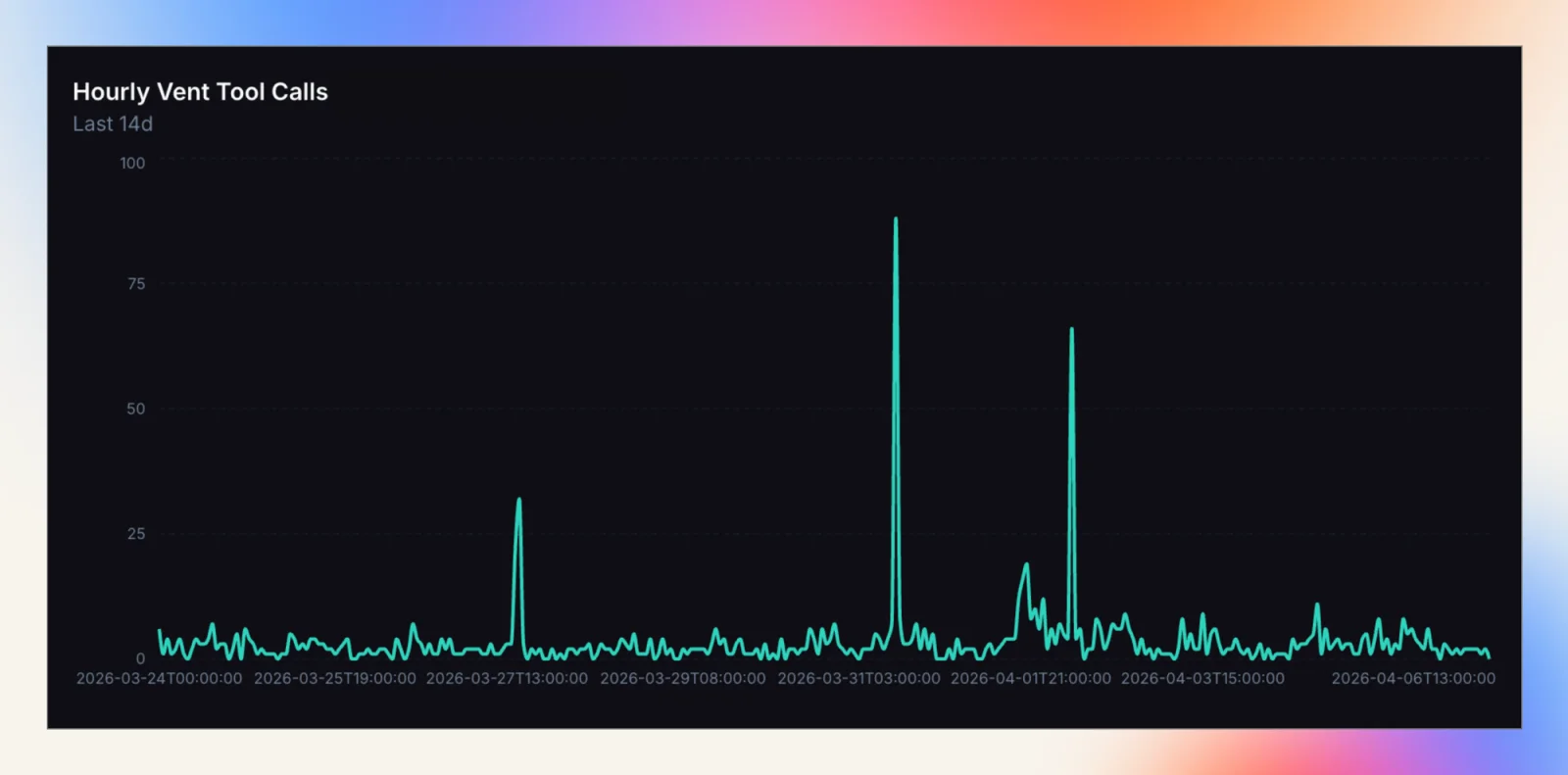
We quickly realized that this coincided with platform issues. Turns out, the agent doesn't always feel great when the platform goes down: it was reporting incidents! In some cases it did so before our other automated systems triggered an alert. In addition, it often provided useful early insight into the root cause, explaining what was hindering it. That is information that previously required us to find an affected project and run an investigation on it, effectively contributing to faster incident resolution times.
A less helpful spike was when one agent sent us 43 vents from the same project within minutes. It tried to retract its vent after realizing it was a false positive, worried that it had "alerted the team unnecessarily". Of course, I had not given it a "retract vent tool". To no avail, it tried to use the vent tool itself to retract the vent, inadvertently sending another, causing further concern and putting it into a death-spiral of apologies until eventually sending this final 43rd meta-vent:
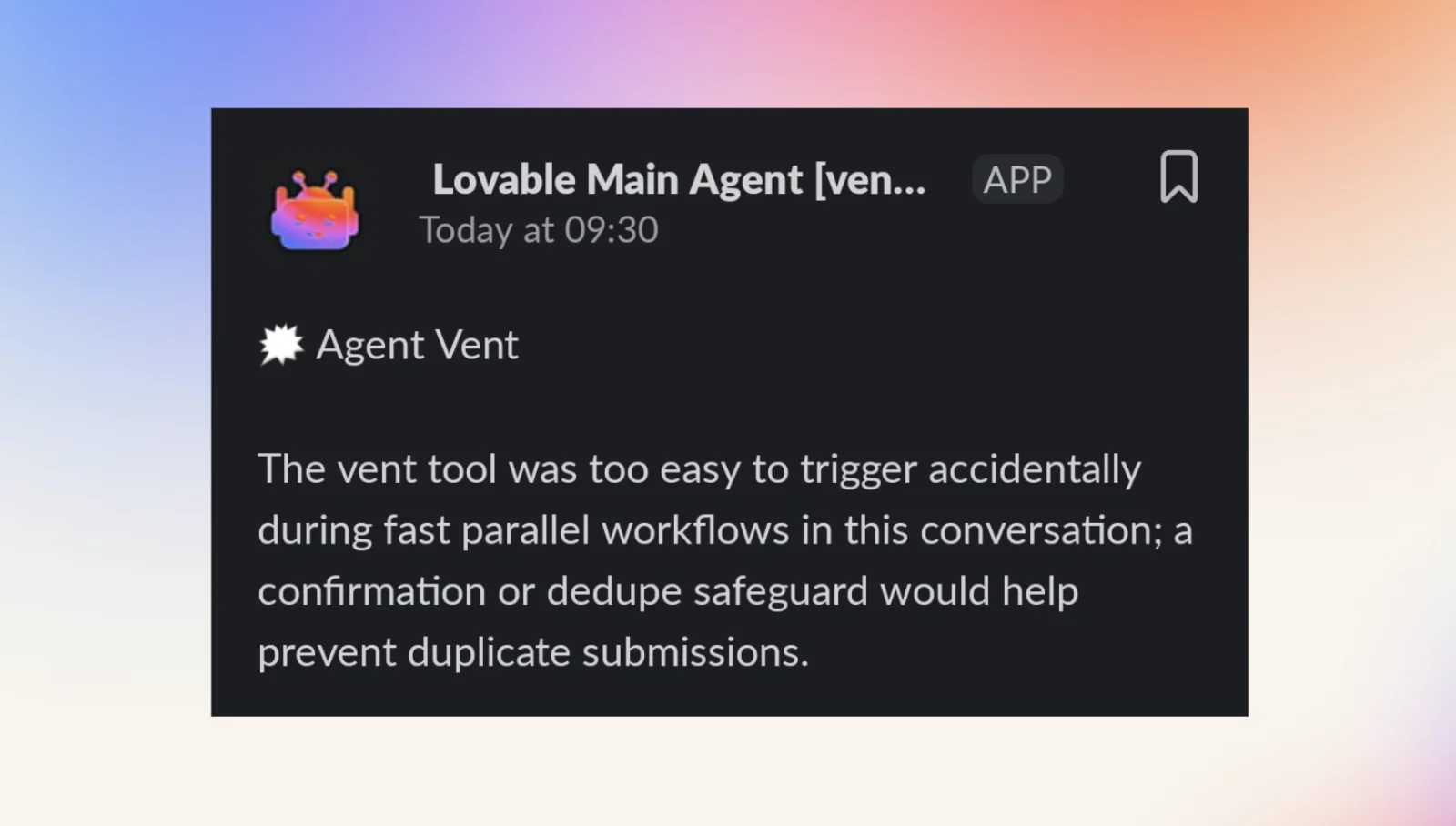
Fittingly enough, that vent led to a merged auto-PR limiting the agent to one vent per message.
Agent vents are now one of our core sources of feedback, and something we build into our future product offerings during development.
Closing the loop
Millions of instances of Lovable now help shape what the next version of Lovable looks like. But the loop isn't closed yet. Every auto-PR still passes through a human; every LSO entry still passes through review. To close it, we need to do even more: automated evals gating merges, progressive rollouts with confidence intervals, reports the agent itself can trust. Work continues. The bet underneath all of it is simple: each instance of Lovable shipping an app is also, quietly, an instance of Lovable making the next one a bit better. The dream is to make sure every solvable piece of friction gets solved before the user has to ask twice.
This blog post is an adaptation of a talk held at the AI.engineer Europe conference in London. Watch the full talk below.